Steven Goodridge's
dissertation is available here on the World Wide Web in HTML
format.
This research involves the synergistic use of sound localization and color vision for tracking human faces and controlling an automatic camera. This is useful for videoconferencing and surveillance applications, and offers new capabilities for human-computer interaction. Inter-aural delay between two microphone signals allows estimation of the direction to sound, while skin tone and motion detection allows the visual sensing of faces and body movement. Information from these sensors is combined ("fused") at the pixel level in order to detect "noisy face pixels" and track the position of the person speaking. This information is used to guide a fuzzy behavior-based camera control system.
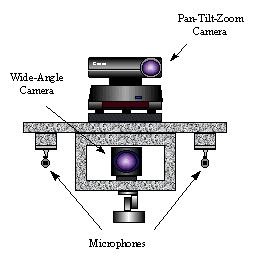
The equipment used for this experiment constists of an ordinary multimedia PC (with a consumer-grade video capture card) attached to two cameras and two microphones, as shown here:
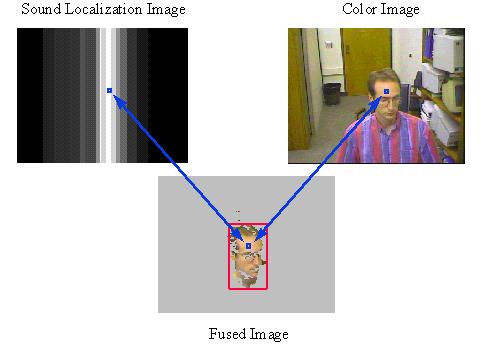
Cross-correlation power of onset signals generated from binaural sound data is combined with skin-tone information at the pixel level to detect "noisy skin-colored pixels" using Bayesian classification techniques:
This information can be tracked for multiple people simultaneously. The following shows face tracking (red) and pure sound localization (green) for a typical tracking experiment where the camera has zoomed in on one person:

When this data is combined with a sophisticated behavior-based control system, automatic control of a camera for videoconferencing can be achieved. The following illustrates how the camera can zoom out to view multiple people speaking, and zoom in when one person dominates the conversation for a long enough period of time:

Future research will involve the combination of this information with speech recognition and voice identification, to determine which person said what word, and interpret this information in the context of the location and identity of the speaker.
This work was supported in part by the National Science Foundation under Grant DMI-9322834.
Keywords: Face tracking, sound localization, face detection, face recognition