In the figure, the sum of the distances from x to the three points in P is 10:

The first step is to transpose x since a 2-element array is interpreted as a column vector, and it needs to be a row vector so that it is compatible with P and can be broadcast so that it can be subtracted from each row in P:


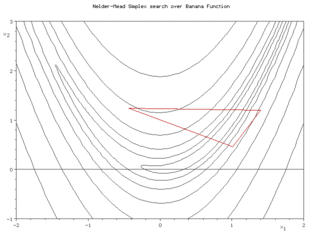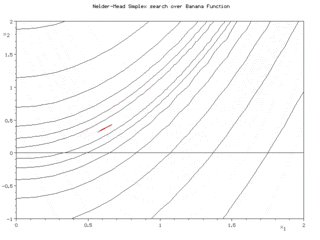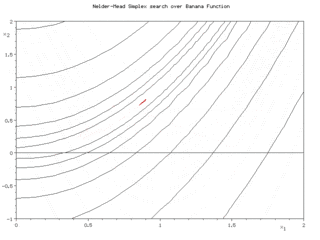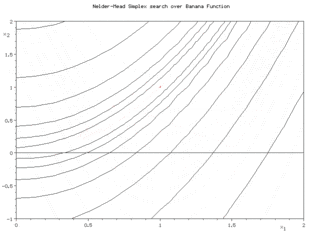{kind=link}