Human beings present a challenge for computer vision. People come in a wide variety of colors, shapes, and sizes, and their shape is not rigid or easily described by geometry. To complicate matters, the environment we live in typically presents a cluttered background. Human beings may easily spot people in a black and white photograph, thanks to our ability to recognize complex spatial patterns based on shape, but today's computer lacks the processing power to accomplish such a feat in real time. Instead, the computer must extract simple features from the current camera image that provide evidence toward the presence of a human being. The visual features chosen for this work are inspired by two early vision processing tasks performed in the eyes of many animals. Most sighted animals use visual motion to spot potential prey or predators moving in the field of view. Color is extremely important to many animals when finding food; for example, bees rely heavily on ultraviolet colors to find flowers. The system described in this work uses both motion and skin tone to detect human beings and their faces as measured by a video camera.
The simplest way to detect a human being visually is through motion in the camera image. Successive frames captured by a stationary camera may be subtracted to generate a difference image, which may be used alone to detect moving targets or used to calculate optical flow. The present image may also be compared to a reference image of the empty room, which can allow excellent segmentation of mobile targets. In this case, care must be taken to maintain the accuracy of the reference image should lighting and clutter locations change. Target detection methods based on differences in gray-scale images are presented by Rao et al. [35], Murray and Basu [36], Karmann and von Brandt [105], Brofferio et al. [106], and Wiklund and Granlund [107]. An optical-flow based system for tracking people in a surveillance application is described by Nichols and Naylor [108]. Murray and Basu [36] demonstrate an image translation scheme to compensate for camera motion. Background image maintenance techniques are described by Karmann and von Brandt [105] and Brofferio et al. [106].
Given the high computational requirements for optical flow, a simple image-difference technique was used to detect moving targets. Between two images, the color difference for each pixel is a distance metric of the form
![]()
where ![]() are the magnitudes of the
difference between the present and reference image R, G, and B pixel
components, and P is an integer exponent greater than zero. For P =
1, this is the rectilinear "Manhattan" distance; for P = 2 it is the
Euclidean distance; and for P it becomes the maximum of {R, G, B}.
Each of these has been tested and satisfactory object detection
obtained with all three. The squared Euclidean distance (P = 2) was
chosen for implementation in target detection since it provides good
noise immunity yet is fast to compute (without needing the square
root).
are the magnitudes of the
difference between the present and reference image R, G, and B pixel
components, and P is an integer exponent greater than zero. For P =
1, this is the rectilinear "Manhattan" distance; for P = 2 it is the
Euclidean distance; and for P it becomes the maximum of {R, G, B}.
Each of these has been tested and satisfactory object detection
obtained with all three. The squared Euclidean distance (P = 2) was
chosen for implementation in target detection since it provides good
noise immunity yet is fast to compute (without needing the square
root).
Color difference provides significantly better segmentation than gray-scale difference. Consider the color image difference segmentation shown in Figures 26, 27, and 28. To extract the target pixels, the squared Euclidean distance between pixel values in the first two images is determined. Those pixel locations with a distance above a threshold are drawn in the third image. Although the target includes many pixels that are the same intensity as the background, their chromatic information allows them to be separated. Note that by transforming the RGB values to another color space based on chromaticity, one might weigh the difference calculation to concentrate on the hue difference and minimize the effect of intensity difference. This would provide superior rejection of noise caused by lighting variation and shadows.
Figures 29 and 30 show the detection of motion between images using color difference. Note that, when there is little motion between frames, few pixels will show change, making it difficult to detect a face or body in its entirety. This makes motion detection better suited for tracking fast-moving objects like vehicles or people walking than for detecting a person who sits relatively still.
Figure 30: Inter-Frame Difference
Figure 28 illustrated how a foreground object may be detected by using background image subtraction. If an image of an empty room is captured with a stationary camera, then people may be detected and tracked using this technique, as shown in Figures 31 and 32.
Figure 32: Original Camera Image
These images were captured using a fish-eye lens, which allows a large field of view (over 90 degrees) to be surveyed at once. In order to reduce the effect of background changes such as lighting variations and furniture movement, one must maintain the reference image over time. This may be accomplished by updating the reference image at each frame snap according to the equation
![]()
where Iref is the reference image (including all three RGB components), Ic is the current image captured from the camera, and B is an array containing a separate gain value for each pixel. The elements of B range from zero to one (although a limit less than one may be used) and serve as a mask for updating the reference image. One may obtain B by looking for motion in the most recent images, and integrating it into a motion history image, D. If there is recent motion in part of the image, or if it is believed that part may be occupied by a human target, then corresponding pixels of B will be zero; for example:
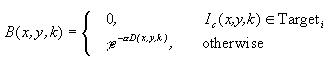
where and define the sensitivity of the update to motion. The motion history image may be defined as
![]()
where the IIR filter coefficients a and b determine the dynamic response of the image. Any motion in the image will rapidly push B to zero. If certain areas of the image have been still and contain no interesting targets, then B for those pixels will increase. Thus moving targets will not be assimilated into the reference image, but completely stationary objects and gradual lighting changes will. Figures 33, 34, and 35 show an object being assimilated into a reference image.
Figure 33: Original Reference Image
Figure 34: Object Being Assimilated into Image
Figure 35: Final Reference Image
Color-based face detection and tracking systems are described by Yang and Waibel [109] and Yoo and Oh [110]. Yang and Waibel use a probabilistic classifier to detect skin-color pixels based on chromaticity, while Yoo and Oh detect likely face locations via Swain and Ballard's color histogram backpropagation technique [111]. Face localization using artificial neural networks is described by Hunke and Waibel [10] and Rowley, Baluja, and Kanade [8]. In [10], only those image areas similar to skin-tone colors are processed by the neural network, improving real-time performance over the scheme used in [8], which exhaustively searches the entire scene. Both of these approaches assume frontal-looking faces. Pentland, Moghaddam, and Starner [20] use a probabilistic Eigenspace-based method to detect the pose and precise position of a face. This technique is applied by Darrell, Moghaddam, and Pentland [15], where background image subtraction is used as a cue to determine the coarse localization of the head in the image. Given the efficiency and invariance to head orientation displayed by the color-based techniques in [109] and [110], skin color was selected as the visual feature to use for detecting faces in this dissertation research.
The color of pixels in the image of a person's face varies across the face, depending on the tissue color, illumination brightness, illumination angle, surface angle, and viewing angle. This variation in color most be considered when designing a color-based face detector. One approach is to model the color distribution of the entire face with a histogram of discrete bins. For detection, the image must be searched for face-sized regions of pixels that match the color histogram model, using histogram backpropagation [111,110]. The main drawback of this technique is the computation required to apply (i.e., convolve) the face-sized histogram operator to every pixel in the image. Another problem with using the entire face for a histogram is that the color distribution may not be face-independent. People with different colored hair, lips or eyeglasses could likely have significantly different histograms, which might make this technique more useful for differentiating between people than for detecting generic faces in an image. Rather than processing an entire face-neighborhood at a time, a single-pixel skin tone classifier (followed by efficient filtering and region growing operations) may be used for face detection. This saves computation and depends on only the statistics of skin tissue color. In order to design a color classifier, some basic principles of color reflection should be considered.
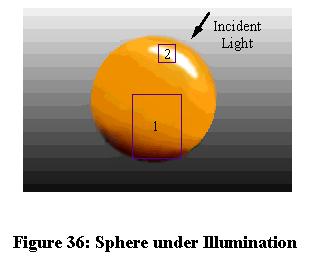
The variation in color reflected by a uniform, opaque dielectric material is discussed by Klinker [112], who describes a dichromatic reflection model and its use in color image segmentation. Two types of light reflection affect the appearance of this class of objects. The first type is body reflection, and is caused by light that penetrates the surface of the material and is scattered and partially absorbed before exiting the material. The second type, surface reflection, is due to the difference in refractive index between the air and object surface, and is maximized where the surface normal bisects the angle between the viewer and light source. This may also be called shine or glare, and is usually brighter than the rest of the object. Figure 36 depicts how a uniformly colored sphere will appear given a directed illumination source. Region 1 shows an area of the sphere that is visible through body reflection, and region 2 shows an area with a strong surface reflection. The design of the skin tone detector described here will rely on body reflection for proper classification, since surface reflection looks similar for many types of surfaces.
Figure 36: Sphere under Illumination
The body and surface reflection components combine to effect the color on each point on the object surface. The light reflected from the object is expressed by Klinker [112] as
![]()
where Ls is the surface component, Lb is the body
component, ![]() is the
wavelength under consideration, i is the illumination
incidence angle, e is the exit angle toward the viewer, and
g is the phase between i and e. The surface and
body reflection terms may each be broken down into their spectral
components, Cs(
is the
wavelength under consideration, i is the illumination
incidence angle, e is the exit angle toward the viewer, and
g is the phase between i and e. The surface and
body reflection terms may each be broken down into their spectral
components, Cs(![]() ) and
Cb(
) and
Cb(![]() ), and their corresponding
geometric scale factors, ms(i,e,g) and
mb(i,e,g), as follows:
), and their corresponding
geometric scale factors, ms(i,e,g) and
mb(i,e,g), as follows:
![]() (3)
(3)
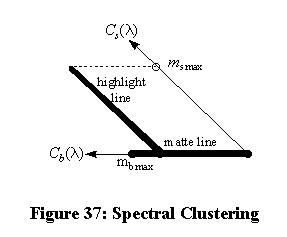
Thus the surface orientation of the object affects the intensity of the surface and body reflections, but not their spectra. The observed color is the sum of scaled versions of the surface reflection and body reflection vectors, as illustrated in Figure 37. The color measured from an object such as a sphere will be clustered along two lines: the matte line, where body reflection grows up from the shadows, and the highlight line, where surface reflection adds to the body reflection and produces a shine effect.
Figure 37: Spectral Clustering
Since the orientation of facial components in a new image are not known, the geometric scaling terms will be denoted simply as ms and mb. The color CCD camera used in this work captures light frequencies near the colors red, green, and blue, so Equation (3) may be rewritten in vector form as
![]() (4)
(4)
where
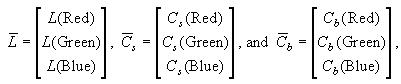
which describes the color value as measured by the camera.
Surface reflection can become very strong on portions of an object. The color of the light from these points is often close to white, and may be indistinguishable from the surface reflections of other materials or pure white objects. Thus the material of an object is not easy to classify on the basis of single-pixel color information in those areas with high surface reflection. In images of a human face taken with overhead lighting, surface reflections can be pronounced on parts of the forehead, nose, or cheekbones, but the rest of the face is usually dominated by body reflection. In designing a statistical classifier for skin tone, a decision must be made on how to handle these surface reflections. If surface reflections are included in the training data for the classifier, then false negative detections of shiny face areas will be reduced, but false positive detections in other parts of the image will likely increase. However, if shiny surfaces are omitted from the training data for the classifier, it may be sufficient to detect the face based on body reflection alone, and either ignore the missing pixels that were not segmented with the face or add them using an algorithm such as relaxation labeling [113].
For the system presented in this dissertation, surface
reflection highlights are ignored by the classifier, and only those
pixel values that lie along or near the body reflection vector ![]() are labeled as skin pixels. It is
necessary to measure vector direction independently of vector
amplitude (intensity), so a color space transformation is made to
reduce the 3D color vector
are labeled as skin pixels. It is
necessary to measure vector direction independently of vector
amplitude (intensity), so a color space transformation is made to
reduce the 3D color vector ![]() to its 2D
chromatic components labeled r and g. This
transformation (denoted by '
to its 2D
chromatic components labeled r and g. This
transformation (denoted by '![]() ') must satisfy
the following intensity invariance rule:
') must satisfy
the following intensity invariance rule:
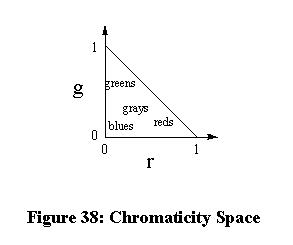
where A is a scalar. This condition is satisfied by the transformation equations
![]() (5)
(5)
The vector magnitude ![]() could also have
been used in the denominator, but would require more arithmetic
operations to compute. Since the real-time performance of image
processing operations are extremely sensitive to the number of
computations done on each pixel, the transformation in (5) is
preferable. The resulting 2D color space is illustrated in Figure 38.
could also have
been used in the denominator, but would require more arithmetic
operations to compute. Since the real-time performance of image
processing operations are extremely sensitive to the number of
computations done on each pixel, the transformation in (5) is
preferable. The resulting 2D color space is illustrated in Figure 38.
Let the (r,g) pixel chromaticity pair be represented as the
vector ![]() . The mean and covariance of
. The mean and covariance of ![]() was determined for pixels manually
selected from face images. During selection of the training set,
portions of the faces that featured obvious surface reflection
highlights were omitted from the population, providing more accurate
statistics of the body reflection vector. The statistics of the
chromaticity population were then used to classify pixels as skin or
background depending on the strength of the probability density
modeled as a Gaussian function:
was determined for pixels manually
selected from face images. During selection of the training set,
portions of the faces that featured obvious surface reflection
highlights were omitted from the population, providing more accurate
statistics of the body reflection vector. The statistics of the
chromaticity population were then used to classify pixels as skin or
background depending on the strength of the probability density
modeled as a Gaussian function:
![]() (6)
(6)
where m is the skin chromaticity sample mean and K is its covariance. Note that this scheme is sensitive to changes in the color of illumination, but this is assumed to be approximately constant within the room.
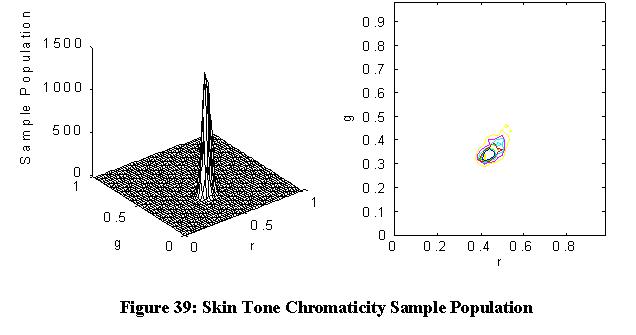
As described in [109], skin tone chromaticity varies little between races, compared to the intensity variation. This may be due to differences in the amount of melanin in the skin, which affects the amount of light absorption, but has little or no change in spectral characteristics between individuals. The statistical classifier was trained from a sampling of ten people with a variety of races and skin tones, including dark African-American and pale Anglo-Saxon skin. Figure 39 shows the chromaticity population distribution for skin tone pixels sampled from ten people. For pixels with very low intensity, sensor noise makes chromaticity information inaccurate. Such pixels are darker than any of the face samples, but can be falsely detected by the classifier. A brightness heuristic was therefore added to the classifier, in order to reject pixels whose luminance was below a given threshold.
Figure 39: Skin Tone Chromaticity Sample Population
Figure 40: Image of the Author
Figure 41: Detection of Skin Pixels
Figure 42: Detection of Faces by Choosing the Largest Skin Tone-Colored Region
Figures 40 and 41 show the performance of this statistical classifier on an image of the author, with a threshold taken at 0.2. Detection of skin colored pixels is good; false positives are detected from earth tones like wood-grains, which are similar in chromatic space to many skin types, and from some vertical edges due to NTSC video artifacts. Figure 42 shows the results of choosing the largest skin-colored region in each of six face images. The following variables were found to affect the performance of the classifier:
The image-difference and statistical skin-tone detection methods presented in this chapter allow human beings to be detected in an unstructured indoor environment. The image-difference technique is ideally suited for applications that allow a stationary wide-angle camera and involve a significant amount of target motion. This may be exploited in surveillance and room control applications. The color-based face detection method is well suited for low-motion applications like videoconferencing, where the camera will zoom in closer to the subject's face. The skin-tone classifier's main weakness, false detection of skin-colored background objects, may be remedied by adding a more intelligent pattern recognition system to qualify face regions after they are detected (e.g., through region size and shape). However, another solution is to reject those pixels that do not coincide with the direction of the sound of the subject's speech, as will be described in the next chapter.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}