The research presented in this dissertation involves the use of multimedia sensors and multisensor fusion and target tracking techniques. Background information on the use of multimodal sensors for human-computer interaction (HCI) applications is presented in Section 2.1. Concepts in multisensor fusion are presented in Section 2.2.
Research into machine perception of people spans multiple disciplines, and approaches vary widely depending on the intended application. While some work has been directed toward the goal of creating anthropomorphic intelligent agents capable of recognizing speech and conversing with people, other work has focused on detecting human body movements as an input device to virtual reality systems. Research topics in HCI technology that extend beyond the keyboard and mouse to include input devices such as cameras and microphones are often referred to as "multimodal interfaces." An overview of many multimodal interface research goals and concepts is provided by Waibel, Minh, Duchnowski, and Stefan [6].
The vast majority of literature to date describing multimedia input devices involves component technologies such as speech recognition working alone or added to the familiar keyboard-mouse-CRT work environment. Another frequent assumption in these applications is that the person being perceived is deliberately cooperating with the perception process, e.g. speaking slowly and repeating misidentified words, or holding their face centered in front of a camera so their lips and expression may be observed. While this is realistic for interactive applications where the person is working directly with the computer, it is quite different from the passive observation scenario described in this dissertation. However, each of these component technologies is important for machine perception of people, and they may be used together to form more intelligent systems. Several of the core technologies in this area are described below.
The recognition of spoken words in isolation or in the context of a sentence is generally referred to as speech recognition, as distinguished from speaker recognition, which refers to matching sampled words with the identity of the speaker (See Footnote 4). While speaker recognition technology most often is targeted at security applications, speech recognition research is by far the larger field, intending to replace much of our use of the keyboard and make computers more accessible. While speech recognition systems are still far from perfect, commercial speech dictation software products are available for multimedia PCs at the time of this writing, offering word recognition rates of over 95% in dictation scenarios. Current challenges facing speech recognition systems include speaker independence, context-based recognition, removal of background noise, and interpretation of natural language. While a thorough discussion of speech recognition technology and relevant references is beyond the scope of this dissertation, some specific techniques that have been used to extend and enhance the recognition process through the addition of other senses will be discussed later in this chapter.
The visual detection and localization of faces in a scene is a useful technique for identifying people, and in the dynamic case, measuring their behavior. In video communications between people, a subject's upper torso and face are the most likely portions of the body to be within view. If computers are ever to communicate with people on an anthropomorphic level, machines will have to interpret similar images and recognize the face as an important and diverse human feature. Yet while the differences between our faces make it possible to tell one another apart, these differences complicate the task of automated detection and extraction of faces from a background scene. Thus the localization process must be designed to detect what is similar about human faces, distinguishing them from clutter in the environment. In addition to human-computer interaction applications, face localization is also useful in low-bandwidth video coding in order to maximize the number of bits used in critical areas of the face while reducing data elsewhere [7]. Numerous face detection schemes based on neural networks [8,9,10], texture analysis [11], fuzzy logic [12], symmetry measurement [13], motion detection [14], background subtraction [15], and color segmentation [10,11,16,110] have been reported. These detection techniques are discussed in Chapter 4.
In addition to localizing faces in the world, matching of faces against images of known persons is also possible. Face recognition algorithms implemented with neural networks [17,18], Bayesian methods [19,20], and fuzzy logic [21] are described in the literature. Besides making human-computer interaction more user-friendly, face recognition technology also has applications for security-related ID verification [22]. A survey of face recognition methods is provided by Chellappa, Wilson, and Sirohey [23].
Human beings communicate a great deal of information about their emotional state through their facial expression. Such information may be useful to a computer in obtaining feedback about its performance in interactive applications. Techniques recognizing human facial expressions are discussed in [24,25,26]. Sensing dynamic changes in face shape is also useful for lip reading, in both the silent recognition case [27] or in conjunction with audio for performance gains over sound-only speech recognition [28,29,30].
For surveillance, virtual-reality, and interactive "smart" room applications, computer vision allows computers to track a human being's position and body pose. The ALIVE system developed at the Massachusetts Institute of Technology's Media Lab tracks human body movements and uses them to control an animated version of the user in a virtual world, rendered onto a large screen in real time [31,32,33]. At Carnegie Mellon University, a 360-degree sensing system integrating motion video from 51 cameras is used to capture abundant 3-D depth information to determine human body position and pose [34]. Simpler human-tracking systems using background image difference [35,16] and motion detection [36] have also been described in the literature. To detect nonverbal communication such as pointing and waving, computer vision systems may employ gesture recognition techniques [37,38,39].
The inter-aural signal differences between two or more microphones allow the direction of a sound source to be estimated. This information is useful for aiming a camera at the source, focusing a beamforming microphone array on the source, and for identifying which person or object caused the sound. Inter-aural signal differences include Interaural Time Difference (ITD) and Interaural Intensity Difference (IID). ITD provides a measure of the difference in distance to the target from each microphone, allowing triangulation, and is frequently calculated using cross-correlation techniques [40,41,42,43]. Additional sound localization systems are presented by [44,45,46,47].
At the time of this writing, PictureTel, a leading videoconferencing systems manufacturer, has begun marketing an automatic camera control system called LimeLightTM which uses sound localization to point the camera at the person speaking. Camera control research platforms using similar schemes are described by [16,48,49]. Beamforming systems, which remove background noise and improve sound quality by electronically steering a microphone array at the desired source, are presented by [48,50, 51,52].
Descriptions of sensing methods that combine both acoustic and visual sensing are quite rare in the literature. The most prevalent are the lip reading systems previously described, which involve close time registration of audio and visual data, but have no concern for spatial registration due to the assumption that only one voice and one face are present. Spatial data association between multiple visual targets and multiple sound sources is described by Wasson [49]. Wasson's system performs symbolic data association after discrete sound and visual targets have been detected separately. Pixel-level fusion used to reinforce spatial sound and motion vision information is described by Takahashi and Yamasaki [52]. In this dissertation, the synergistic use of sound localization data and color vision at an early level of processing will be used to detect people.
The terms sensor integration and sensor fusion both refer to the use of multiple sensor data in an intelligent system. A common, but not universally accepted, distinction may be made here. Sensor integration usually refers to the use of the multiple sensors to provide information for different sub-tasks during different modes of a system's operation. An example may be an industrial robot that uses a vision system to locate parts, and a touch sensor to assist its grasp while lifting a part, but segregates these sensing modalities to different steps in the task. Sensor fusion usually refers to the combination of multiple sensor data into one representation or control action, for improved measurement accuracy or motor behavior. For example, a robot might use the combined features of weight, shape, and color to classify and sort objects. Or, it might fuse multiple sensor readings to localize itself or objects in its environment. The boundary between integration and fusion is fuzzy and, for the most part, arbitrary. The distinction is made only to draw attention to the more difficult problems associated with sensor fusion, such as finding a common representation for data from multiple sensor types, resolving differences between measurements, and registering sensors to one another.
Sensor fusion may be performed on time series, redundant, and/or complementary sensor data. Time series fusion, by far the most common, allows for filtering of noisy sensor data and is commonly used in target tracking applications. Redundant sensors acquire data in parallel, and allow comparisons to be made among simultaneous readings. An example of this is the use of multiple ultrasonic range finders on a mobile robot for obstacle detection and avoidance. Complementary, or multimodal sensor fusion incorporates information about different physical aspects of the environment. This multimodal case is of special interest to our audio/visual tracking system. Multimodal sensor data is often used in recognition and world modeling tasks.
Applications of multisensor fusion may be characterized by the level of representation given to data during the fusion process, and by the mathematical foundation upon which the fusion operation is based. In Section 2.2.1, the issue of levels of representation are explored. In Section 2.2.2, the theoretical basis for several popular fusion techniques are compared.
The form taken by sensor data at the point of fusion varies depending on how early in processing this combination takes place. Luo and Kay [53] describe four common levels of fusion: signal level, pixel level, feature level, and symbol level, to which a fifth, behavior level, may be added. A comparison of fusion levels is given in Table 1, adapted from [53] with the addition of behavior level fusion.
|
|
|
|
|
|
|
|
Type of sensory information |
|
|
|
|
|
|
Representation level of information |
|
|
|
|
|
|
Model of Sensory Information |
|
|
|
|
|
|
Degree of registration spatial: temporal |
|
|
|
|
|
|
Means of registration spatial: |
|
|
|
|
|
|
temporal: |
|
|
|
|
|
|
Fusion method |
|
|
|
|
|
|
Improvement due to fusion |
|
|
|
|
|
Note that these levels of fusion are only a rough classification of representation possibilities, and in no way can capture the subtlety of numerous applications. For instance, pixel-based images such as those used in medical imaging may be treated as spatially discrete two-dimensional non-causal signals. Despite the obvious pixel-based representation of these signals, the mathematical techniques used to process and fuse this data are more closely related to signal-based techniques [54,55,56]. In contrast, cellular spatial models of the world often benefit from pixel-level fusion techniques. Range signals from sensors such as sonar and laser-radar may be incorporated into a grid model to synthesize an "image" of the environment for extraction of features as a later step [57], [58].
2.2.1.1 Signal-Level Fusion
When one hears an insect buzzing above and behind one's head, one can approximately localize and track the insect using the information one's ears provide over time. Such is an example of signal-level fusion. Inter-aural time and intensity differences in the ears are processed to provide an estimate of the insect's position. One's hearing becomes tuned to the sound detected, and the accumulation of direction measurements gives one a more accurate estimate of its location.
Approaches to signal-level fusion incorporate multi-sensor or time-series data to improve the quality of the signal. The most common techniques consist of filtering or weighted averaging. An overview of the popular Kalman filtering method is given in Chapter 6.
2.2.1.2 Pixel-Level Fusion
When an object moves within one's field of view, the time variation of the image projected onto the retina is detected as motion. The point of activity on the retina maps directly to the target's azimuth and elevation in space. This type of pixel-level fusion demonstrates the power of a data representation that contains implicit spatial information in its structure.
Pixel-level fusion may be performed on time-series images, images from stereo or trinocular cameras, or multiple sensors with shared optics. Additional types of sensor measurements may be fused into images that serve as cellular representations of the world. Time-series pixel data can be used for optical flow and target tracking, while stereo or trinocular fusion allows extraction of depth information through triangulation of matched pixels in each image. Images generated by different sensors types through separate apertures are difficult to fuse due to the registration problems of parallax and image warping. To simplify this, some multimodal imaging systems use shared optics. An example of fusion between manually registered forward-looking infrared and intensity images for automatic target recognition is given in [59]. In such cases, a multimodal vectored pixel element can provide greater sensitivity in the detection phase than can the original, unregistered scalar pixel elements of either sensor.
Cellular world models also present an opportunity for pixel-level fusion from the same or multiple sensor modalities. In medical imaging, for example, tomagraphic techniques are used to synthesize images from sensor data for CT, MR, and PET scans. Elfes [57] demonstrates the fusion of multiple ultrasonic rangefinder measurements into a probabilistic map of occupied spaces. Beckerman [60] uses a 2-D cellular world map for the fusion of visual and ultrasonic sensor data. Richardson and Marsh [61] demonstrate the fusion of elevation data from downward-looking ultrasonic range measurements and structured lighting vision to form an elevation map of an object.
2-D or 3-D cellular maps of the environment are powerful representations for fusing sensor data. They can directly represent spatial relationships between areas of the world for which data is available, without increasing in size as more data is gathered. Sensors of different spatial resolutions may be represented by choosing a cell size appropriate for the highest resolution sensor and blurring the projection of lower-resolution data onto the map. On the down side, processing of cellular models may be computationally intensive, and require large amounts of memory, especially when fusing time-series pixel data.
2.2.1.3 Feature Level Fusion
When one negotiates a staircase, one can locate the limits of the stair treads by noting the edges due to boundaries of color and texture, and abrupt differences in depth. One may also feel the tread with one's foot. The fusion of these different features provide a reliable position estimate for the stair edge.
Feature level fusion involves the sensory extraction of object features in the environment so that they may be matched to corresponding features in a symbolic world model. For instance, a mobile robot may measure the distance to walls using sonar, and detect the straight edges of walls and doors using vision. It may then match these features to a geometric map of world to estimate its position or update the map. Wallner and Dillman [62] use feature-level fusion to match stereo vision and sonar data to a parametric model of an indoor environment. Cox [63] demonstrates the matching of infrared range data to a geometric map. Abdulgafour and Abidi [64] fuse edge features from intensity and range images for better segmentation of facets of geometric objects. Broida [65] illustrates a technique for matching features detected in multiple sensor measurements.
2.2.1.4 Symbol-Level Fusion
When used together, symbols like the words apple, serpent, garden, deity, and Eve can evoke a specific idea in one's brain. Visual or acoustic information is used to detect the words, then symbolic reasoning and memory recall take over. Using relationships between symbols, and between one's senses and symbols, allows high-level logical decision making and a more compact representation of concepts, especially for information processed computers.
The most common type of symbol-level fusion is pattern recognition. Feature information is extracted from sensor data, defining a point in feature-space. This point may be mapped to a symbolic interpretation of the world based on that symbol's neighborhood in feature space. Such a neighborhood function may be defined by probability theory [66], Dempster-Shafer's theory of evidence [67], crisp or fuzzy logic [68,69], neural networks [70], or other means.
In problems such as speech recognition, the classification task involves multiple inter-dependent classifications. Vocabulary, rules of grammar, and context can greatly assist in constraining the range of possible phonemes or words that match a particular sequence of data. The Hidden-Markov Model approach to this problem is described in [71]. Duchnowski et al. [28] demonstrate improvement of machine speech recognition through the addition of visual lip-reading.
Symbol-level fusion usually assumes that sensor measurements correspond exclusively to the specific object (e.g., an unidentified target) or event (e.g., an unidentified phoneme spoken) that caused them. If measurements of multiple objects or events are present in the data set, proper association must be performed before recognition and symbolic reasoning can be performed. Given the complexity of the data association problem and difficulty of data separation in some cases, most descriptions of symbolic reasoning schemes ignore cases where multiple objects or events could be present in the data, e.g., multiple faces in an image [28], multiple people speaking at once [71], or affliction by more than one disease [72]. Given this dissertation's application of tracking people in a room where multiple people and sound disturbances will be present, it is obvious that these recognition techniques will not work without proper data association and separation, where appropriate.
2.2.1.5 Behavior Level Fusion
When one reaches to activate a light switch, multiple motor skills are simultaneously responsible for guiding the limb. One's reach begins with a ballistic motion, using an estimation of the dynamics necessary to reach that target in space. As the hand draws near the switch, one may visually correct the motion if it is off-target. Upon contact, the sense of touch provides feedback for fine adjustments to properly activate the switch. During much of the motion, more than one of these low-level control processes are active at once, a fact of which one is not acutely aware. This is evidence of a type of low-level behavior fusion, where multiple control behaviors overlap and combine to perform tasks smoothly.
Behavior fusion is useful for intelligent systems that must perform autonomous activities based on sensor information. For many years, research in robotics and artificial intelligence was dominated by the sense-model-plan-act paradigm, where all control actions were deliberatively determined from an internal world model and subsequently executed. The problems with this approach were the poor reliability of a world model constructed from noisy, uncertain sensor data, and the inability to incorporate and react to new sensor information in a time-effective manner. As a result, autonomous robots and systems did not perform well in unstructured environments. However, a new paradigm recommended by Brooks [73] proposed that robot control be broken into parallel, concurrent reactive behaviors that could interact with one another and respond to new sensor data in real time. Each behavior would be competent in its own limited domain, and subsumed by other behaviors when the robot was outside that domain. Rather than planning a path around every object, a robot's goal seeking behavior could simply attempt to drive toward the goal, but would be overridden by an obstacle avoidance behavior when its path was not clear. Robots designed around this philosophy proved to be faster, far more responsive to environmental stimuli, and able to recover gracefully from mistakes [74,75].
Several techniques exist for combining separate behaviors. In Brooks' subsumption architecture [73], behaviors can operate concurrently, especially when affecting different actuators, such as an arm and a wheel, or can be switched on and off by a hierarchy of finite state machines. Sensor measurements and timers were used to determine state transitions, with limited use of internal world models. Arkin [76] uses artificial potential fields to fuse control recommendations from multiple behaviors, which he calls "schemas." Pin et al. [77] define reactive robot control behavior using fuzzy rules processed by custom VLSI fuzzy inferencing hardware. Goodridge and Luo [78], Goodridge, Luo, and Kay [79], and Goodridge [80] use an efficient fuzzy control inference kernel to define and fuse a hierarchy of behaviors for mobile robot guidance. Fuzzy rules define separate reactive behaviors as well as the way in which these separate recommendations are blended into the motor control signal. This technique allowed the mobile robot MARGE to win an event at a national competition for intelligent mobile robots in 1993 [81].
Behavior-level techniques cannot completely replace high-level planning and reasoning. Rather, they provide a degree of real-time low-level competence in reacting to sensor data, while higher level processing may optimize strategies and assign sub-goals. In some applications, however, behavior-level fusion provides graceful degradation and error recovery well enough that high level planning becomes unnecessary [80]. We may also find this to be true for the application of tracking a human being; for example, losing track of the current speaker may be gracefully recovered from by a behavior such as widening the field of view until the system regains a reliable track.
Independent of the level of representation used, a variety of popular mathematical techniques for sensor fusion appear in the literature. These methods generally perform a data-reduction mapping from multiple inputs to a smaller number of outputs. Inputs may be raw sensor readings, pixel values, extracted features, signal estimators, or control signals; outputs may be estimated state, recognized objects or events, enhanced features, control signals, etc. In this section, the strengths and weaknesses of each method will be explored. An important aspect of each technique is the way in which it models uncertainty in sensor information. An excellent overview of uncertainty formalizations, and the relationships between them, is given by Klir [82].
2.2.2.1 Probability and Bayesian Inference Techniques
Probability theory, which measures the likelihood of an event, was first developed by Blaise Pascal in the 17th century as a means of solving gambling problems. It was later advanced by Thomas Bayes in the 18th Century and by Pierre de Laplace in the early 19th century. Probability-based inference techniques have withstood mathematical scrutiny for hundreds of years, and are the foundation of most sensor fusion applications.
The basic assumption of probability-based sensor fusion is that the uncertainly in sensor information may be modeled by uncorrelated random noise. (However, Beckerman [60] demonstrates a Bayesian Maximum Entropy technique for multisensor fusion given non-random systematic noise.) Decision and estimation rules based on probability include mean-square error and maximum a-posterior probability (MAP), which minimize the probability of error, Bayes risk, which minimizes the probable cost of error, and maximum likelihood, which estimates a parameter without assuming a prior probability distribution for values of the parameter. An introduction to these methods is given in [66].
Probability theory provides optimal decision and estimation results for systems in which accurate statistics can be gathered or calculated from the structure of the problem. The testing of a probability-based decision system requires determining frequency ratios through experimentation. This reinforces the widely held frequency definition of probability, disputed by Cheeseman [83], which he describes as follows:
The probability of an event (hypothesis) is the ratio of the number of occurrences (n) in which the event is true to the total number of such occurrences (m).
Cheeseman argues that the frequency definition of probability is unnecessarily limiting, and that probability may be applied to more general applications of uncertainty in artificial intelligence if a different definition is accepted [83]:
The (conditional) probability of a proposition given particular evidence is a real number between zero and one, that is a measure of an entity's belief in that proposition, given the evidence.
Cheeseman points out that this belief definition of probability is more intuitive than the frequency definition. It allows probability theory to be applied to AI systems which attempt to model degrees of belief, and may be a superior replacement to theories such as Dempster-Shafer's theory of evidence and fuzzy logic. Cheeseman is correct in his assertion that probability is equivalent or superior to these other techniques in many applications. However, it is the opinion of this author that the approaches taken by the inventors of these alternatives have contributed much to the understanding of uncertainty in intelligent systems, and have expedited the development of successful applications. For this reason, the alternative methods in question are included in this review.
Probability theory provides the foundation for optimal filter/estimators such as the Kalman Filter, described in Chapter 6, which is used in many applications for target tracking, robot localization, and system control. Examples of Bayesian techniques for fusion of sensor data into cellular maps are illustrated by Elfes [57], Beckerman [60], and Richardson and Marsh [61]. MAP decision rules provide a powerful means for pattern recognition and classification [66,71]. Bayesian techniques are commonly used for image restoration and pixel classification [55,54,56].
2.2.2.2 Dempster-Shafer Theory of Evidence
The theory of evidential combination proposed by Dempster [84] and
extended by Shafer [67] models uncertainty as belief in one or more
propositions or ignorance. The set of all possible mutually exclusive
hypothesis is called the frame of discernment,![]() . With each evidential proposition, one or more members
of the power set of
. With each evidential proposition, one or more members
of the power set of ![]() (denoted 2^
(denoted 2^![]() ) are assigned a basic probability
assignment (bpa) number in the range [0, 1]. One member of 2^
) are assigned a basic probability
assignment (bpa) number in the range [0, 1]. One member of 2^![]() , denoted simply as
, denoted simply as![]() , is assigned a bpa representing a
proposition's ignorance of which hypothesis is correct. This
representation of ignorance is what makes Demster-Shafer reasoning
different from probability For instance, in probability theory, the
probabilities of mutually exclusive hypothesis sum to one, that is,
, is assigned a bpa representing a
proposition's ignorance of which hypothesis is correct. This
representation of ignorance is what makes Demster-Shafer reasoning
different from probability For instance, in probability theory, the
probabilities of mutually exclusive hypothesis sum to one, that is,
Pr[A] + Pr[ ¬A] = 1.
In the Dempster-Shafer Theory, the bpa belief mass for each mutually exclusive hypothesis may sum to less than one:
m(A) + m(¬A) <= 1
where, instead,
m(A) + m( ¬A) + m( ![]() ) <= 1
) <= 1
Evidence gathering accumulates belief in each hypothesis set Ck
(subset of 2^![]() ) according to
Dempster's rule of combination:
) according to
Dempster's rule of combination:
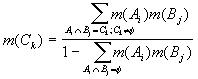
The belief of a hypothesis set Ck is defined as
![]()
The plausibility of the hypothesis set Ck is define as one minus the belief in the complement of Ck:
Pls(Ck) = 1 - Bel( ¬Ck)
As evidence is gathered, the rule of combination increases the belief and plausibility of those hypotheses supported by the evidence, and decreases the bpa of the ignorance factor, (. If no weight is assigned to ignorance, Dempster's rule of combination reduces to basic probability theory. It is intuitively appealing to model ignorance in this way, especially when evidence is supplied from human experts. Indeed, Dempster-Shafer reasoning is often applied to expert systems that reason using epistemic, more often than aleatory, representations of belief.
An illustration of the Dempster-Shafer theory applied to medical diagnosis is given by Gordon and Shortliffe [85]. Stein [86] gives an example of finding the most likely suspect of a crime using subjective interpretation of evidence. In more quantitative applications, Lee [56] and Lee and Leahy [54] compare the use of Dempster-Shafer, MAP, and maximum likelihood algorithms for multi-sensor image segmentation problems, showing a marginal improvement in the results of the Dempster-Shafer implementations over MAP. (ML ignores the prior introduced by a Markov Random Field used in the other methods and, therefore, resulted in a much higher misclassification rate.)
Hughes and Murphy [58] apply Dempster-Shafer reasoning to a cellular world map constructed from sonar data. By assigning degrees of ignorance to cells for which little or no data is available, their method can distinguish between unmapped areas and cells which show inconsistent data, or "strife," after repeated measurements. Consequently, a cell with equal probability of being empty or occupied may be thought to exist on an edge or in a dynamic region if ignorance is low. This differentiation from unmapped cells is not possible with the Bayesian mapping technique presented by Elfes [57].
Hutchinson and Kak [87] demonstrate dynamic planning of sensing strategies to minimize ambiguity through Dempster-Shafer reasoning in recognition of geometric objects. They generate 2-D and 3-D features using structured lighting and intensity images, as well as force/torque features from sensor in the wrist of a robot manipulator. Sensing strategies are chosen dynamically by searching for the next sensing operation that would minimize the maximum ambiguity in the resulting hypothesis set given the evidence present at each iteration.
The advantages of Dempster-Shafer evidential reasoning are best displayed in applications that: (a) combine subjective expert knowledge, (b) involve class hierarchies of hypotheses, and (c) benefit from the explicit modeling of ignorance and strife as separate uncertainty metrics. However, Cheeseman [83] argues that these features can be provided equally well by Bayesian techniques. For instance, it is possible to measure the probability of error in a probability estimation; this value decreases with the addition of evidence just as the Dempster-Shafer "ignorance" value does. Given the strong mathematical history of probability theory, Dempster-Shafer reasoning remains controversial, but it has nevertheless enabled some significant applications of data fusion in uncertainty.
2.2.2.3 Fuzzy Logic and Fuzzy Control Behaviors
Fuzzy set theory, originally developed by Zadeh [68] in the 1960s, has become a popular tool for control applications in recent years. The principle behind this field allows ambiguous information to be classified into sets that do not have crisp boundaries; hence the name "fuzzy sets." Given a measurement x, a fuzzy set A is said to contain x with a degree of membership defined as µA(x), where µA(x) can be any value in the continuous domain [0,1]. Fuzzy sets are usually named after adjectives, such as TALL; the membership function described as µTALL(x) would therefore reflect the similarity between values of x and the contextual meaning of TALL. If x represented a person's height in centimeters, and TALL were used to classify "tall men," then µTALL might have a membership function equal to zero below 150 cm, equal to one over 185 cm, and a smooth curve of fractional values between these limits. The degree of truth of a statement like "If Bob's height is TALL ..." is evaluated by calculating the value of the membership function for Bob's height. A fuzzy set may also be thought of as a distance metric for the comparison of quantitative data. Fuzzy set memberships are often take the shape of Gaussian, trapezoidal, or sigmoidal functions.
Logical manipulation of fuzzy memberships requires the extension of crisp logic operations to fuzzy sets. The three fundamental logical operations, intersection, union, and complement, have fuzzy counterparts popularly defined as follows:
Intersection ( x is A ) AND ( y is B ): A and B = min ( µA(x), µB(y) )
Union ( x is A ) OR ( y is B ): A or B = max ( µA(x), µB(y) )
Complement ( x is not A ): ¬A = 1 - µA(x)
Applications using fuzzy techniques can generally be divided into two groups: fuzzy logic, and fuzzy control. In fuzzy logic, fuzzy sets provide a multi-valued belief representation for constraint-based reasoning. They also provide a way to characterize a region of an expert system's potentially large input space, using linguistic terms that are easy for human beings to specify. Fuzzy systems may be adaptively trained to partition the input space and develop rules for recognition and classification tasks. Gibson, Hall, and Stover [88] demonstrate the application of fuzzy logic to automatic target recognition. Abdulghafour and Abidi [64] use fuzzy rules to fuse edge data from range and intensity images for better image segmentation. An introduction to fuzzy reasoning and applications may be found in [69].
The most popular application of fuzzy techniques is for control systems. Fuzzy sets and rules allow a system designer to define control signal recommendations at various points in the controller's input space. The shapes of the fuzzy sets used define the interpolation that occurs between fuzzy rules. This provides the capabilities of a nonlinear control surface without complex mathematics; rather, the system designer only needs an intuitive sense of the problem in order to write linguistic rules. The output of a fuzzy controller may be determined using the centroid of the fuzzy rule recommendations as follows: If each rule i prescribes an output value of oi with an antecedent certainty of wi, then the output of a controller with N rules is calculated as follows:
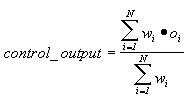
Fuzzy control allows the representation of one form of uncertainty, "vagueness," in the description of control rules. It does not assume to represent the behavior of random events, and thus has no counterpart in probability theory. It is therefore relatively immune to the criticisms of fuzzy set theory and fuzzy logic by those advocate purely probabilistic models of uncertainty. Some examples of applications of fuzzy control may be found in [89,77,90,91,78]. In earlier work, the present author used multiple layers of fuzzy controllers to define control behaviors for a mobile robot [80]. Similar techniques may be used in order to control a pan-tilt-zoom camera according to qualitative expert rules for the surveillance and videoconferencing applications presented in this dissertation.
2.2.2.4 Neural Networks
Inspired by the connection-oriented architecture of biological intelligence and sensory systems, adaptive learning through artificial neural networks has received considerable attention in the areas of pattern recognition [92] and control systems [93]. Much of this work followed the development of gradient-descent learning training algorithms for multi-layer feedforward networks during the 1980's, spurred by the recent increase in availability of computing power for iterative calculations. An introduction to neural network techniques, including feedforward nets, supervised training by backpropagation, Kohonen nets, and Hopfield nets is provided in [70].
Unlike fuzzy systems, whose pattern classification or control mapping function is usually directly programmed by a human expert, neural systems adapt to example training data using supervised (e.g., backpropagation) or unsupervised (e.g., Kohonen) learning techniques. The objective of training the network is to generalize the classification or control mapping from the sample data. Early in training, a feedforward network's neurons have low activation levels, providing very shallow transitions between regions in the input space. These slopes steepen as training progresses, until the function closely matches outputs required for the sample data at those points. Training is usually stopped as soon as a minimum error threshold is reached in order to prevent overtraining, which can adversely affect generalization. Classification neighborhoods realized by multilayer neural networks can take virtually any shape. In contrast, Bayesian modeling and classification usually involves a limiting assumption of the shape of the density functions, e.g., Gaussian. For many complex systems, neural networks provide a powerful means for adaptive learning of a classification or control mapping.
Out of the variety of multimedia and sensor fusion topics covered in this chapter, the following concepts apply directly to the research presented in this dissertation:
In the next two chapters, the mechanisms used for sound localization and color vision are presented.